작가:
Roger Morrison
창조 날짜:
4 구월 2021
업데이트 날짜:
1 칠월 2024

콘텐츠
대부분의 사람들은 수직선에서 숫자를 읽거나 그래프에서 데이터를 읽는 데 익숙합니다. 그러나 표준 척도는 특정 상황에서 유용하지 않습니다. 데이터가 기하 급수적으로 증가하거나 감소하는 경우 로그 척도를 사용해야합니다. 예를 들어, 시간이 지남에 따라 판매 된 맥도날드 버거의 수는 1955 년 100 만 개에서 시작될 것입니다. 1 년 후 5 백만 개가 넘었고 1990 년에는 4 억, 10 억 (10 년 미만) 및 최대 800 억에 달합니다.이 데이터는 표준 그래프에 비해 너무 많지만 로그 스케일로 쉽게 표현할 수 있습니다. 로그 스케일은 표준 스케일 에서처럼 균일 한 간격이 아닌 숫자를 나타내는 다른 시스템을 가지고 있습니다. 로그 스케일을 읽는 방법을 알면 데이터를보다 효과적으로 읽고 그래픽으로 표시 할 수 있습니다.
단계로
방법 1/2 : 그래프 축 읽기
 하나 또는 두 축이 로그 척도를 사용하는지 확인합니다. 빠르게 증가하는 데이터를 보여주는 차트는 하나 또는 두 개의 로그 척도가있는 축을 사용할 수 있습니다. 차이점은 x 축과 y 축이 모두 로그 스케일을 사용하는지 아니면 하나만 사용하는지입니다. 선택은 그래프에 표시하려는 세부 정보의 양에 따라 다릅니다. 한 축 또는 다른 축의 숫자가 기하 급수적으로 증가하거나 감소하는 경우 해당 축에 대수 눈금을 사용할 수 있습니다.
하나 또는 두 축이 로그 척도를 사용하는지 확인합니다. 빠르게 증가하는 데이터를 보여주는 차트는 하나 또는 두 개의 로그 척도가있는 축을 사용할 수 있습니다. 차이점은 x 축과 y 축이 모두 로그 스케일을 사용하는지 아니면 하나만 사용하는지입니다. 선택은 그래프에 표시하려는 세부 정보의 양에 따라 다릅니다. 한 축 또는 다른 축의 숫자가 기하 급수적으로 증가하거나 감소하는 경우 해당 축에 대수 눈금을 사용할 수 있습니다. - 로그 (또는 단순히 "로그") 눈금에는 불규칙한 격자 선이 있습니다. 표준 축척에는 균일 한 간격의 그리드 선이 있습니다. 일부 데이터는 표준 종이에만, 일부는 세미 로그 차트에, 일부는 로그 로그 차트에 그려야합니다.
- 예 : 그래프
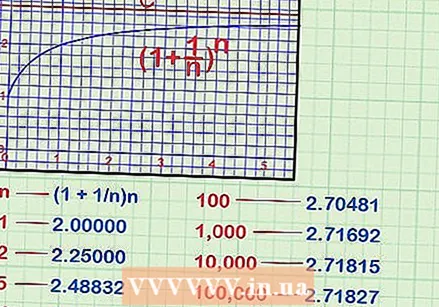 주요 분류의 척도를 읽으십시오. 로그 스케일 차트에서 균등 한 간격의 마커는 작업중인 밑의 힘을 나타냅니다. 표준 로그는 기본 10 또는 자연 로그를 사용합니다.
주요 분류의 척도를 읽으십시오. 로그 스케일 차트에서 균등 한 간격의 마커는 작업중인 밑의 힘을 나타냅니다. 표준 로그는 기본 10 또는 자연 로그를 사용합니다.  작은 간격은 균등 한 간격이 아닙니다. 대수 그래프 용지를 사용하는 경우 기본 장치 간의 간격이 균등하지 않은 것을 알 수 있습니다. 즉, 예를 들어 20에 대한 표시는 실제로 10과 100 사이 거리의 약 1/3에 배치됩니다.
작은 간격은 균등 한 간격이 아닙니다. 대수 그래프 용지를 사용하는 경우 기본 장치 간의 간격이 균등하지 않은 것을 알 수 있습니다. 즉, 예를 들어 20에 대한 표시는 실제로 10과 100 사이 거리의 약 1/3에 배치됩니다. - 부 간격은 각 숫자의 로그를 기반으로합니다. 따라서 10이 척도의 첫 번째 주요 표시로 표시되고 100이 두 번째로 표시되면 다른 숫자는 다음과 같이 그 사이에 속합니다.
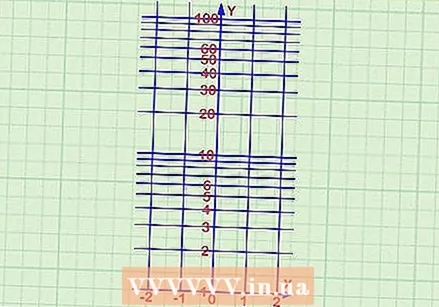 사용하려는 스케일 유형을 결정하십시오. 아래 설명에서 초점은 x 축에 대한 표준 스케일과 y 축에 대한 로그 스케일을 사용하는 세미 로그 그래프에 있습니다. 그러나 데이터를 보는 방법에 따라이 값을 되돌릴 수 있습니다. 축을 반전하면 그래프가 90도 이동하고 데이터를 한 방향 또는 다른 방향으로 더 쉽게 해석 할 수 있습니다. 또한 로그 스케일을 사용하여 특정 데이터 값을 분산하고 세부 정보를 더 잘 볼 수 있습니다.
사용하려는 스케일 유형을 결정하십시오. 아래 설명에서 초점은 x 축에 대한 표준 스케일과 y 축에 대한 로그 스케일을 사용하는 세미 로그 그래프에 있습니다. 그러나 데이터를 보는 방법에 따라이 값을 되돌릴 수 있습니다. 축을 반전하면 그래프가 90도 이동하고 데이터를 한 방향 또는 다른 방향으로 더 쉽게 해석 할 수 있습니다. 또한 로그 스케일을 사용하여 특정 데이터 값을 분산하고 세부 정보를 더 잘 볼 수 있습니다.  x 축의 눈금을 표시하십시오. x 축은 독립 변수입니다. 독립 변수는 측정 또는 실험에서 일반적으로 제어하는 변수입니다. 독립 변수는 연구에서 다른 변수의 영향을받지 않습니다. 독립 변수의 몇 가지 예는 다음과 같습니다.
x 축의 눈금을 표시하십시오. x 축은 독립 변수입니다. 독립 변수는 측정 또는 실험에서 일반적으로 제어하는 변수입니다. 독립 변수는 연구에서 다른 변수의 영향을받지 않습니다. 독립 변수의 몇 가지 예는 다음과 같습니다. - 데이트
- 시각
- 나이
- 주어진 약물
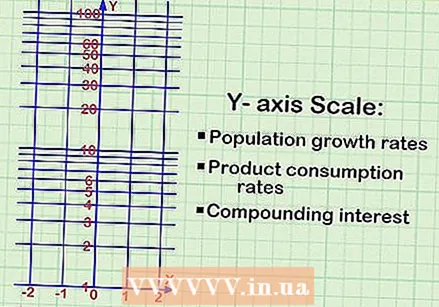 y 축에 로그 스케일이 필요한지 확인합니다. 로그 척도를 사용하여 매우 빠르게 변화하는 데이터를 매핑합니다. 표준 차트는 선형 방식으로 증가하거나 감소하는 데이터에 유용합니다. 로그 그래프는 기하 급수적으로 변화하는 데이터를위한 것입니다. 이러한 데이터의 예는 다음과 같습니다.
y 축에 로그 스케일이 필요한지 확인합니다. 로그 척도를 사용하여 매우 빠르게 변화하는 데이터를 매핑합니다. 표준 차트는 선형 방식으로 증가하거나 감소하는 데이터에 유용합니다. 로그 그래프는 기하 급수적으로 변화하는 데이터를위한 것입니다. 이러한 데이터의 예는 다음과 같습니다. - 인구 증가
- 소비
- 복리
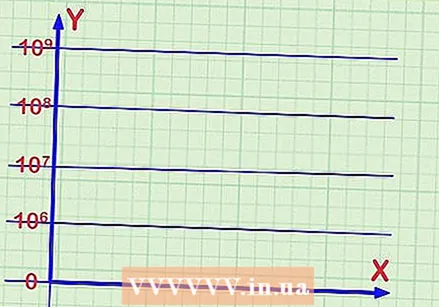 로그 스케일에 레이블을 지정하십시오. 데이터를 검토하고 y 축 표시 방법을 결정합니다. 예를 들어 데이터가 수백만에서 수십억 이내의 숫자 만 측정한다면 그래프를 0에서 시작할 필요가 없습니다. 차트에서 가장 낮은주기에 다음과 같이 레이블을 지정할 수 있습니다.
로그 스케일에 레이블을 지정하십시오. 데이터를 검토하고 y 축 표시 방법을 결정합니다. 예를 들어 데이터가 수백만에서 수십억 이내의 숫자 만 측정한다면 그래프를 0에서 시작할 필요가 없습니다. 차트에서 가장 낮은주기에 다음과 같이 레이블을 지정할 수 있습니다.  데이터 포인트의 x 축 위치를 찾습니다. 첫 번째 (또는 임의의) 데이터 포인트를 그래프로 표시하려면 먼저 x 축을 따라 위치를 찾습니다. 이것은 정규 숫자 라인 1, 2, 3 등과 같은 오름차순 스케일 일 수 있습니다. 특정 측정을 수행하는 날짜 또는 월과 같이 사용자가 지정하는 레이블 스케일 일 수 있습니다.
데이터 포인트의 x 축 위치를 찾습니다. 첫 번째 (또는 임의의) 데이터 포인트를 그래프로 표시하려면 먼저 x 축을 따라 위치를 찾습니다. 이것은 정규 숫자 라인 1, 2, 3 등과 같은 오름차순 스케일 일 수 있습니다. 특정 측정을 수행하는 날짜 또는 월과 같이 사용자가 지정하는 레이블 스케일 일 수 있습니다. 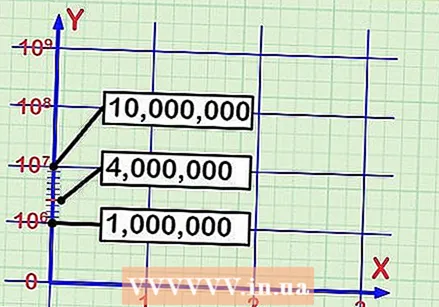 대수 y 축을 따라 위치를 찾습니다. 플로팅하려는 데이터의 y 축을 따라 해당 위치를 찾아야합니다. 로그 스케일로 작업하고 있으므로 메이저 마커는 10의 거듭 제곱이고 그 사이의 마이너 스케일 마커는 세분화입니다. 예 : 사이
대수 y 축을 따라 위치를 찾습니다. 플로팅하려는 데이터의 y 축을 따라 해당 위치를 찾아야합니다. 로그 스케일로 작업하고 있으므로 메이저 마커는 10의 거듭 제곱이고 그 사이의 마이너 스케일 마커는 세분화입니다. 예 : 사이 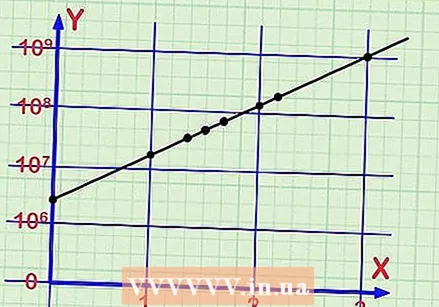 모든 데이터를 계속합니다. 차트를 만드는 데 필요한 모든 데이터에 대해 이전 단계를 계속 반복합니다. 각 데이터 포인트에 대해 먼저 x 축을 따라 위치를 찾은 다음 y 축의 로그 스케일을 따라 해당 위치를 찾습니다.
모든 데이터를 계속합니다. 차트를 만드는 데 필요한 모든 데이터에 대해 이전 단계를 계속 반복합니다. 각 데이터 포인트에 대해 먼저 x 축을 따라 위치를 찾은 다음 y 축의 로그 스케일을 따라 해당 위치를 찾습니다.
- 부 간격은 각 숫자의 로그를 기반으로합니다. 따라서 10이 척도의 첫 번째 주요 표시로 표시되고 100이 두 번째로 표시되면 다른 숫자는 다음과 같이 그 사이에 속합니다.
경고
- 로그 스케일에서 데이터를 읽는 경우 로그에 사용되는 밑을 알고 있는지 확인하십시오. 베이스 10에서 측정 된 데이터는베이스 e로 자연 로그 스케일에서 측정 된 데이터와 매우 다를 것입니다.



