작가:
Virginia Floyd
창조 날짜:
8 팔월 2021
업데이트 날짜:
20 6 월 2024

콘텐츠
Spearman 순위의 상관 계수를 사용하면 단조 함수로 표현되는 두 변수 사이에 종속성이 있는지 여부를 결정할 수 있습니다(즉, 한 변수가 증가하면 두 번째는 증가하고 그 반대도 마찬가지임). 이 기사에 제공된 간단한 단계를 통해 수동으로 계산을 수행하고 Excel 및 R을 사용하여 상관 계수를 계산할 수 있습니다.
단계
방법 1/3: 수동으로 계산
 1 데이터 테이블을 만듭니다. 이것은 Spearman 순위 상관 계수를 계산하는 데 필요한 정보를 구성합니다. 이 경우 다음이 필요합니다.
1 데이터 테이블을 만듭니다. 이것은 Spearman 순위 상관 계수를 계산하는 데 필요한 정보를 구성합니다. 이 경우 다음이 필요합니다. - 위와 같이 6개의 열이 표시됩니다.
- 변수 쌍의 수에 해당하는 라인 수입니다.
 2 변수 쌍으로 처음 두 열을 채우십시오.
2 변수 쌍으로 처음 두 열을 채우십시오. 3 세 번째 열에는 1에서 1까지의 변수 쌍의 수(순위)를 기록하십시오. NS (총 쌍 수). 첫 번째 열에서 가장 낮은 값을 가진 쌍에 숫자 1을 할당하고 그 다음 값에 2를 할당하는 식으로 첫 번째 열에서 변수 값의 오름차순으로 숫자를 할당합니다.
3 세 번째 열에는 1에서 1까지의 변수 쌍의 수(순위)를 기록하십시오. NS (총 쌍 수). 첫 번째 열에서 가장 낮은 값을 가진 쌍에 숫자 1을 할당하고 그 다음 값에 2를 할당하는 식으로 첫 번째 열에서 변수 값의 오름차순으로 숫자를 할당합니다.  4 네 번째 열에서 세 번째 열과 동일하게 수행하되, 이번에는 표의 두 번째 열에 따라 변수 쌍의 번호를 지정합니다.
4 네 번째 열에서 세 번째 열과 동일하게 수행하되, 이번에는 표의 두 번째 열에 따라 변수 쌍의 번호를 지정합니다.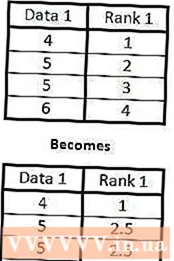 한 열에 있는 변수의 두 개(또는 그 이상) 값이 같으면 차례로 정렬하고 숫자의 평균을 찾은 다음 이 평균으로 번호를 매깁니다.
한 열에 있는 변수의 두 개(또는 그 이상) 값이 같으면 차례로 정렬하고 숫자의 평균을 찾은 다음 이 평균으로 번호를 매깁니다.
오른쪽 예에서 변수의 두 값은 동일하고 5와 같습니다. 정상적인 번호 매기기의 경우 이러한 데이터는 순위 2와 3을 받습니다. 값이 같기 때문에 순위의 평균 값을 찾습니다.2와 3의 평균은 2.5이므로 둘 다 2.5의 순위를 지정합니다.
 5 열 "d"에서 이전 두 열의 두 순위 간의 차이를 계산합니다. 예를 들어, 세 번째 열의 순위가 1이고 네 번째 열의 순위가 3이면 그 차이는 2가 됩니다. 다음 단계에서 이 숫자가 제곱되기 때문에 부호는 중요하지 않습니다.
5 열 "d"에서 이전 두 열의 두 순위 간의 차이를 계산합니다. 예를 들어, 세 번째 열의 순위가 1이고 네 번째 열의 순위가 3이면 그 차이는 2가 됩니다. 다음 단계에서 이 숫자가 제곱되기 때문에 부호는 중요하지 않습니다.  6 열 "d"의 각 값을 제곱하고 열 "d"에 결과 값을 씁니다.
6 열 "d"의 각 값을 제곱하고 열 "d"에 결과 값을 씁니다.- 7"d"열의 모든 값을 추가하십시오. 합계 Σd를 결정합니다.

- 8 다음 공식 중 하나를 사용하십시오.
- 이전 단계에서 동일한 값을 충족하지 않는 경우 결과 합계를 단순화된 공식으로 대체하여 Spearman의 순위 상관 계수를 계산하기만 하면 됩니다.

"n"을 이전에 테이블에 입력한 데이터 쌍의 수로 바꿉니다.
- 이전 단계에서 동일한 값을 발견하면 표준 공식을 사용하여 Spearman의 순위 상관 계수를 계산합니다.

- 이전 단계에서 동일한 값을 충족하지 않는 경우 결과 합계를 단순화된 공식으로 대체하여 Spearman의 순위 상관 계수를 계산하기만 하면 됩니다.
- 9 결과를 분석합니다. 결과 값은 -1과 1 사이입니다.
- -1에 가까우면 상관 관계가 음수입니다.
- 0에 가까우면 상관관계가 없습니다.
- 1에 가까우면 양의 상관관계가 있는 것입니다.
- 변수의 합으로 나누고 근을 취하는 것을 잊지 마십시오. 그런 다음 Σd로 나눕니다.
방법 2/3: Excel에서 계산
- 1 데이터 열에 해당하는 순위로 새 열을 만듭니다. 예를 들어, 데이터가 A2 열: A11에 입력된 경우 "= RANK (A2, A $ 2: A $ 11)" 함수를 사용하고 새 열의 모든 행에 대한 결과를 입력합니다.
- 2방법 1의 3단계와 4단계에서 설명한 대로 동일한 수량에 대한 순위를 찾습니다.
- 3 새 셀에서 "= CORREL (C2: C11, D2: D11)" 함수를 사용하여 두 순위 열 간의 상관 관계를 확인합니다. 이 경우 C와 D는 순위를 포함하는 열입니다. 따라서 이 셀에서 Spearman의 순위 상관 계수를 얻을 수 있습니다.
방법 3/3: R에서 계산
- 1 통계 처리를 위한 R 소프트웨어가 아직 없으면 구입하십시오(참조: http://www.r-project.org).
- 2 조사할 상관 관계인 두 개의 열에 데이터를 정렬하여 데이터를 CSV 형식으로 저장합니다. "다른 이름으로 저장" 옵션을 사용하여 이 형식으로 파일을 쉽게 저장할 수 있습니다.
- 3 R 편집기를 엽니다. R 프로그램에 아직 로그인하지 않았다면 시작하십시오. 이렇게 하려면 바탕 화면에서 R 아이콘을 클릭하기만 하면 됩니다.
- 4 다음 명령을 입력합니다.
- d - read.csv("NAME_OF_YOUR_CSV.csv") 및 Enter 키를 누릅니다.
- cor (순위 (d [, 1]), 순위 (d [, 2]))
팁
- 일반적으로 데이터 세트는 상관 관계를 안정적으로 설정할 수 있도록 최소 5쌍이어야 합니다(단순성을 위해 위의 예에서는 3쌍을 사용했습니다).
경고
- Spearman의 순위 상관 계수를 사용하면 두 변수가 동시에 증가하거나 감소하는지 여부만 설정할 수 있습니다. 데이터 산포가 너무 크면 이 계수가 ~ 아니다 정확한 상관 값을 제공합니다.
- 주어진 함수는 데이터 배열에 동일한 값이 없으면 올바른 결과를 제공합니다. 이러한 값이 존재하는 경우 이 예에서와 같이 순위 기반 상관 계수 정의를 사용해야 합니다.



