작가:
Judy Howell
창조 날짜:
2 칠월 2021
업데이트 날짜:
1 칠월 2024

콘텐츠
공분산은 두 데이터 세트 간의 관계를보다 투명하게 만드는 통계 계산입니다. 예를 들어 인류학자가 특정 문화 내에서 인구의 키와 몸무게를 연구한다고 가정 해 보겠습니다. 연구에 참여한 각 사람에 대해 한 쌍의 데이터 (x, y)와 함께 키와 몸무게를 표시 할 수 있습니다. 이러한 값은 공분산 관계를 계산하기위한 표준 공식에서 사용할 수 있습니다. 이 문서에서는 먼저 데이터 세트의 공분산을 결정하기위한 계산에 대해 설명합니다. 다음으로 결과를 결정하는 다른 두 가지 자동화 된 방법에 대해 설명합니다.
단계로
방법 1/4 : 표준 공식을 사용하여 손으로 공분산 계산
 표준 공분산 공식과 그 부분에 대해 알아 봅니다. 공분산 계산을위한 표준 공식은 다음과 같습니다.
표준 공분산 공식과 그 부분에 대해 알아 봅니다. 공분산 계산을위한 표준 공식은 다음과 같습니다.  데이터 테이블을 구성하십시오. 시작하기 전에 데이터를 수집하는 것이 좋습니다. 5 개의 열로 구성된 테이블을 만듭니다. 다음과 같이 각 열을 선언해야합니다.
데이터 테이블을 구성하십시오. 시작하기 전에 데이터를 수집하는 것이 좋습니다. 5 개의 열로 구성된 테이블을 만듭니다. 다음과 같이 각 열을 선언해야합니다.  x 데이터 포인트의 평균을 계산합니다. 이 샘플 데이터 세트는 9 개의 숫자를 포함합니다. 평균을 구하려면 이들을 더하고 합계를 9로 나눕니다. 이렇게하면 결과 1 + 3 + 2 + 5 + 8 + 7 + 12 + 2 + 4 = 44가됩니다. 이것을 9로 나누면 평균이됩니다. 4.89. 이것은 다음 계산에 x (avg)로 사용할 값입니다.
x 데이터 포인트의 평균을 계산합니다. 이 샘플 데이터 세트는 9 개의 숫자를 포함합니다. 평균을 구하려면 이들을 더하고 합계를 9로 나눕니다. 이렇게하면 결과 1 + 3 + 2 + 5 + 8 + 7 + 12 + 2 + 4 = 44가됩니다. 이것을 9로 나누면 평균이됩니다. 4.89. 이것은 다음 계산에 x (avg)로 사용할 값입니다.  y 데이터 포인트의 평균을 계산합니다. 이 y 열은 또한 x 데이터 포인트와 일치하는 9 개의 데이터 포인트로 구성되어야합니다. 이들의 평균을 결정하십시오. 이 샘플 데이터 세트의 경우 이는 8 + 6 + 9 + 4 + 3 + 3 + 2 + 7 + 7 = 49가됩니다.이 합계를 9로 나누어 평균 5.44를 얻습니다. 다가오는 계산을 위해 5.44를 y (avg)의 값으로 사용할 것입니다.
y 데이터 포인트의 평균을 계산합니다. 이 y 열은 또한 x 데이터 포인트와 일치하는 9 개의 데이터 포인트로 구성되어야합니다. 이들의 평균을 결정하십시오. 이 샘플 데이터 세트의 경우 이는 8 + 6 + 9 + 4 + 3 + 3 + 2 + 7 + 7 = 49가됩니다.이 합계를 9로 나누어 평균 5.44를 얻습니다. 다가오는 계산을 위해 5.44를 y (avg)의 값으로 사용할 것입니다.  값 계산
값 계산  값 계산
값 계산  각 데이터 행의 제품을 계산합니다. 이전 두 열에서 계산 한 숫자를 곱하여 마지막 열의 행을 채 웁니다.
각 데이터 행의 제품을 계산합니다. 이전 두 열에서 계산 한 숫자를 곱하여 마지막 열의 행을 채 웁니다.  마지막 열에서 값의 합계를 찾으십시오. 여기에 Σ 기호가 들어 있습니다. 지금까지 모든 계산을 수행 한 후 결과를 함께 추가하십시오. 이 샘플 데이터 세트의 경우 이제 마지막 열에 9 개의 값이 있어야합니다. 이 9 개의 숫자를 더하세요. 숫자가 양수인지 음수인지 세심한주의를 기울이십시오.
마지막 열에서 값의 합계를 찾으십시오. 여기에 Σ 기호가 들어 있습니다. 지금까지 모든 계산을 수행 한 후 결과를 함께 추가하십시오. 이 샘플 데이터 세트의 경우 이제 마지막 열에 9 개의 값이 있어야합니다. 이 9 개의 숫자를 더하세요. 숫자가 양수인지 음수인지 세심한주의를 기울이십시오. - 이 샘플 데이터 세트의 합은 -64.57이되어야합니다. 이 합계를 열 하단의 공간에 적으십시오. 이것은 표준 공분산 공식의 분자 값입니다.
 공분산 공식의 분모를 계산합니다. 표준 공분산 공식의 분자는 방금 계산 한 값입니다. 분모는 (n-1)로 표시되며 데이터 세트의 데이터 쌍 수보다 하나 적습니다.
공분산 공식의 분모를 계산합니다. 표준 공분산 공식의 분자는 방금 계산 한 값입니다. 분모는 (n-1)로 표시되며 데이터 세트의 데이터 쌍 수보다 하나 적습니다. - 이 예제 문제에는 9 쌍의 데이터가 있으므로 n은 9입니다. 따라서 (n-1)의 값은 8과 같습니다.
 분자를 분모로 나눕니다. 공분산 계산의 마지막 단계는 분자를 나누는 것입니다.
분자를 분모로 나눕니다. 공분산 계산의 마지막 단계는 분자를 나누는 것입니다.  반복적 인 계산이 무엇인지 주목하십시오. 공분산은 결과의 의미를 이해하기 위해 몇 번 손으로해야하는 계산입니다. 그러나 데이터 해석에 공분산을 일상적으로 사용하려는 경우 결과를 얻기 위해 더 빠르고 자동화 된 방법이 필요합니다. 지금 쯤이면 9 개의 데이터 쌍으로 구성된 비교적 작은 데이터 세트에서 계산이 평균 2 개, 개별 뺄셈 18 개, 곱셈 9 개, 덧셈 1 개, 그리고 마지막으로 또 다른 나눗셈으로 구성되어 있음을 알 수 있습니다. 해답을 찾기위한 상대적으로 작은 계산 31 개입니다. 그 과정에서 부정적인 부호를 놓치거나 결과를 잘못 복사하여 답이 더 이상 정확하지 않을 위험이 있습니다.
반복적 인 계산이 무엇인지 주목하십시오. 공분산은 결과의 의미를 이해하기 위해 몇 번 손으로해야하는 계산입니다. 그러나 데이터 해석에 공분산을 일상적으로 사용하려는 경우 결과를 얻기 위해 더 빠르고 자동화 된 방법이 필요합니다. 지금 쯤이면 9 개의 데이터 쌍으로 구성된 비교적 작은 데이터 세트에서 계산이 평균 2 개, 개별 뺄셈 18 개, 곱셈 9 개, 덧셈 1 개, 그리고 마지막으로 또 다른 나눗셈으로 구성되어 있음을 알 수 있습니다. 해답을 찾기위한 상대적으로 작은 계산 31 개입니다. 그 과정에서 부정적인 부호를 놓치거나 결과를 잘못 복사하여 답이 더 이상 정확하지 않을 위험이 있습니다.  공분산 계산을위한 워크 시트를 만듭니다. Excel (또는 다른 계산 프로그램)에 익숙한 경우 공분산을 결정하기위한 테이블을 쉽게 만들 수 있습니다. 손으로 계산 한 것처럼 x, y, (x (i) -x (avg)), (y (i) -y (avg)) 및 Product라는 5 개 열의 제목에 레이블을 지정합니다.
공분산 계산을위한 워크 시트를 만듭니다. Excel (또는 다른 계산 프로그램)에 익숙한 경우 공분산을 결정하기위한 테이블을 쉽게 만들 수 있습니다. 손으로 계산 한 것처럼 x, y, (x (i) -x (avg)), (y (i) -y (avg)) 및 Product라는 5 개 열의 제목에 레이블을 지정합니다. - 이름 지정을 단순화하려면 데이터의 의미를 기억하는 한 세 번째 열을 "x 차이"와 네 번째 열 "y 차이"라고 부르십시오.
- 표가 워크 시트의 왼쪽 위 모서리에서 시작하면 A1 셀에는 x라는 레이블이 지정되고 다른 레이블은 E1 셀까지 계속됩니다.
 데이터 포인트를 입력하십시오. 두 개의 열 x 및 y에 데이터 값을 입력하십시오. 데이터 포인트의 순서가 중요하므로 각 y를 해당하는 x 값과 일치시켜야합니다.
데이터 포인트를 입력하십시오. 두 개의 열 x 및 y에 데이터 값을 입력하십시오. 데이터 포인트의 순서가 중요하므로 각 y를 해당하는 x 값과 일치시켜야합니다. - x 값은 A2 셀에서 시작하여 필요한 데이터 포인트 수까지 계속됩니다.
- y 값은 셀 B2에서 시작하여 필요한 데이터 포인트 수까지 계속됩니다.
 x 및 y 값의 평균을 결정합니다. Excel은 평균을 매우 빠르게 계산합니다. 각 데이터 열 아래의 첫 번째 빈 셀에 수식 = AVERAGE (A2 : A ___)를 입력합니다. 마지막 데이터 포인트에 해당하는 셀 번호로 빈 공간을 채 웁니다.
x 및 y 값의 평균을 결정합니다. Excel은 평균을 매우 빠르게 계산합니다. 각 데이터 열 아래의 첫 번째 빈 셀에 수식 = AVERAGE (A2 : A ___)를 입력합니다. 마지막 데이터 포인트에 해당하는 셀 번호로 빈 공간을 채 웁니다. - 예를 들어 100 개의 데이터 포인트가있는 경우 A2에서 A101까지의 셀이 채워 지므로 셀에 = AVERAGE (A2 : A101)를 입력합니다.
- y 데이터의 경우 수식 = AVERAGE (B2 : B101)를 입력합니다.
- Excel의 수식은 "="기호로 시작합니다.
 열의 공식을 입력합니다 (x (i) -x (avg)). C2 셀에 첫 번째 빼기를 계산하는 공식을 입력합니다. 이 공식은 다음과 같습니다. = A2 -___. x 데이터의 평균을 포함하는 셀 주소로 공백을 채 웁니다.
열의 공식을 입력합니다 (x (i) -x (avg)). C2 셀에 첫 번째 빼기를 계산하는 공식을 입력합니다. 이 공식은 다음과 같습니다. = A2 -___. x 데이터의 평균을 포함하는 셀 주소로 공백을 채 웁니다. - 예를 들어 100 개의 데이터 포인트 중 평균은 A103 셀에 있으므로 수식은 = A2-A103이됩니다.
 데이터 포인트 (y (i) -y (avg))에 대한 공식을 반복합니다. 같은 예에 따라 D2 셀에 들어갑니다. 공식은 다음과 같습니다. = B2-B103.
데이터 포인트 (y (i) -y (avg))에 대한 공식을 반복합니다. 같은 예에 따라 D2 셀에 들어갑니다. 공식은 다음과 같습니다. = B2-B103.  "제품"열에 대한 공식을 입력하십시오. 다섯 번째 열에서 E2 셀에 수식을 입력하여 앞의 두 셀의 곱을 계산합니다. 그러면 = C2 * D2가됩니다.
"제품"열에 대한 공식을 입력하십시오. 다섯 번째 열에서 E2 셀에 수식을 입력하여 앞의 두 셀의 곱을 계산합니다. 그러면 = C2 * D2가됩니다.  공식을 복사하여 표를 채 웁니다. 지금까지 2 행의 처음 몇 개의 데이터 포인트 만 프로그래밍했습니다. 마우스를 사용하여 셀 C2, D2 및 E2를 표시하십시오. 더하기 기호가 나타날 때까지 오른쪽 아래 모서리에있는 작은 상자에 커서를 놓습니다. 마우스 버튼을 누른 상태에서 마우스를 아래로 끌어 선택 영역을 확장하고 전체 데이터 테이블을 채 웁니다. 이 단계는 셀 C2, D2 및 E2의 세 가지 수식을 전체 테이블에 자동으로 복사합니다. 테이블은 모든 계산으로 자동으로 채워 져야합니다.
공식을 복사하여 표를 채 웁니다. 지금까지 2 행의 처음 몇 개의 데이터 포인트 만 프로그래밍했습니다. 마우스를 사용하여 셀 C2, D2 및 E2를 표시하십시오. 더하기 기호가 나타날 때까지 오른쪽 아래 모서리에있는 작은 상자에 커서를 놓습니다. 마우스 버튼을 누른 상태에서 마우스를 아래로 끌어 선택 영역을 확장하고 전체 데이터 테이블을 채 웁니다. 이 단계는 셀 C2, D2 및 E2의 세 가지 수식을 전체 테이블에 자동으로 복사합니다. 테이블은 모든 계산으로 자동으로 채워 져야합니다.  마지막 열의 합계를 프로그래밍합니다. "제품"열에있는 항목의 합계가 필요합니다. 해당 열의 마지막 데이터 요소 바로 아래에있는 빈 셀에 수식을 입력합니다. = SUM (E2 : E ___). 빈 공간을 마지막 데이터 포인트의 셀 주소로 채 웁니다.
마지막 열의 합계를 프로그래밍합니다. "제품"열에있는 항목의 합계가 필요합니다. 해당 열의 마지막 데이터 요소 바로 아래에있는 빈 셀에 수식을 입력합니다. = SUM (E2 : E ___). 빈 공간을 마지막 데이터 포인트의 셀 주소로 채 웁니다. - 100 개의 데이터 요소가있는 예에서이 수식은 E103 셀로 이동합니다. 유형 : = SUM (E2 : E102).
 공분산을 결정합니다. Excel에서 최종 계산을 수행하도록 할 수도 있습니다. 이 예제에서 E103 셀의 마지막 계산은 공분산 공식의 분자를 나타냅니다. 해당 셀 바로 아래에 수식을 입력합니다. = E103 / ___. 가지고있는 데이터 포인트의 수로 빈 공간을 채 웁니다. 이 예에서 이것은 100입니다. 결과는 데이터의 공분산입니다.
공분산을 결정합니다. Excel에서 최종 계산을 수행하도록 할 수도 있습니다. 이 예제에서 E103 셀의 마지막 계산은 공분산 공식의 분자를 나타냅니다. 해당 셀 바로 아래에 수식을 입력합니다. = E103 / ___. 가지고있는 데이터 포인트의 수로 빈 공간을 채 웁니다. 이 예에서 이것은 100입니다. 결과는 데이터의 공분산입니다.
4 가지 방법 중 3 : 온라인 공분산 계산기 사용
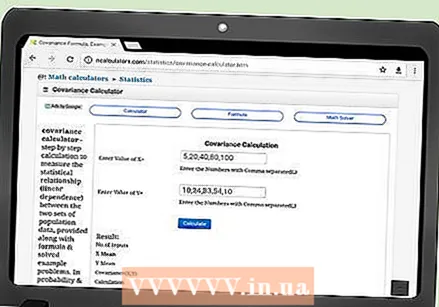 공분산 계산기를 온라인으로 검색하십시오. 다양한 학교, 회사 또는 기타 소스에는 공분산 값을 매우 쉽게 계산하는 웹 사이트가 있습니다. 검색 엔진에서 "공분산 계산기"라는 검색어를 사용합니다.
공분산 계산기를 온라인으로 검색하십시오. 다양한 학교, 회사 또는 기타 소스에는 공분산 값을 매우 쉽게 계산하는 웹 사이트가 있습니다. 검색 엔진에서 "공분산 계산기"라는 검색어를 사용합니다.  세부 정보를 입력하십시오. 웹 사이트의 지침을주의 깊게 읽고 정보를 올바르게 입력했는지 확인하십시오. 데이터 쌍을 순서대로 유지하는 것이 중요합니다. 그렇지 않으면 생성 된 결과가 잘못된 공분산이됩니다. 웹 사이트에는 다양한 스타일의 데이터 입력이 있습니다.
세부 정보를 입력하십시오. 웹 사이트의 지침을주의 깊게 읽고 정보를 올바르게 입력했는지 확인하십시오. 데이터 쌍을 순서대로 유지하는 것이 중요합니다. 그렇지 않으면 생성 된 결과가 잘못된 공분산이됩니다. 웹 사이트에는 다양한 스타일의 데이터 입력이 있습니다. - 예를 들어 http://ncalculators.com/statistics/covariance-calculator.htm 웹 사이트에는 x 값을 입력하는 가로 상자와 y 값을 입력하는 두 번째 가로 상자가 있습니다. 데이터는 쉼표로 구분하여 입력해야합니다. 따라서이 기사의 앞부분에서 계산 된 x 데이터 세트는 1,3,2,5,8,7,12,2,4로 입력해야합니다. y 데이터는 8,6,9,4,3,3,2,7,7입니다.
- https://www.thecalculator.co/math/Covariance-Calculator-705.html의 다른 사이트에서는 첫 번째 상자에 x 데이터를 입력하라는 메시지가 표시됩니다. 데이터는 한 줄에 한 항목 씩 세로로 입력됩니다. 따라서이 사이트의 항목은 다음과 같습니다.
- 1
- 3
- 2
- 5
- 8
- 7
- 12
- 2
- 4
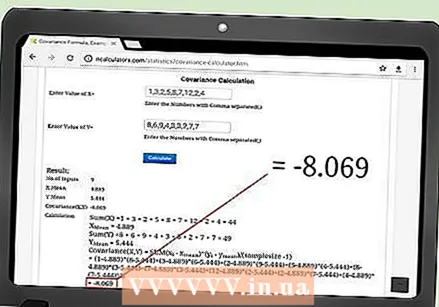 결과를 계산하십시오. 이러한 온라인 계산의 매력적인 점은 데이터를 입력 한 후 일반적으로 "계산"버튼을 클릭하기 만하면 결과가 자동으로 표시된다는 것입니다. 대부분의 사이트는 x (avg), y (avg) 및 n의 중간 계산을 제공합니다.
결과를 계산하십시오. 이러한 온라인 계산의 매력적인 점은 데이터를 입력 한 후 일반적으로 "계산"버튼을 클릭하기 만하면 결과가 자동으로 표시된다는 것입니다. 대부분의 사이트는 x (avg), y (avg) 및 n의 중간 계산을 제공합니다.
4 가지 방법 중 4 : 공분산 결과 해석
 긍정적이거나 부정적인 관계를 찾으십시오. 공분산은 한 데이터 세트와 다른 데이터 세트 간의 관계를 나타내는 단일 통계 숫자입니다. 소개에 언급 된 예에서는 키와 몸무게를 측정합니다. 사람들이 성장함에 따라 체중도 증가하여 긍정적 인 공분산보기로 이어질 것으로 예상 할 수 있습니다. 또 다른 예 : 누군가 골프 연습 시간과 달성 한 점수를 나타내는 데이터가 수집되었다고 가정합니다. 이 경우에는 음의 공분산이 예상됩니다. 즉, 훈련 시간이 증가하면 골프 점수가 감소합니다. (골프에서는 점수가 낮을수록 좋습니다).
긍정적이거나 부정적인 관계를 찾으십시오. 공분산은 한 데이터 세트와 다른 데이터 세트 간의 관계를 나타내는 단일 통계 숫자입니다. 소개에 언급 된 예에서는 키와 몸무게를 측정합니다. 사람들이 성장함에 따라 체중도 증가하여 긍정적 인 공분산보기로 이어질 것으로 예상 할 수 있습니다. 또 다른 예 : 누군가 골프 연습 시간과 달성 한 점수를 나타내는 데이터가 수집되었다고 가정합니다. 이 경우에는 음의 공분산이 예상됩니다. 즉, 훈련 시간이 증가하면 골프 점수가 감소합니다. (골프에서는 점수가 낮을수록 좋습니다). - 위에서 계산 된 샘플 데이터 세트를 고려하십시오. 결과 공분산은 -8.07입니다. 마이너스 기호는 x 값이 증가함에 따라 y 값이 감소하는 경향이 있음을 의미합니다. 일부 값을 살펴보면 이것이 사실임을 알 수 있습니다. 예를 들어, 1과 2의 x 값은 7, 8, 9의 y 값에 해당합니다. 8과 12의 x 값은 각각 3과 2의 y 값에 연결됩니다. .
 공분산의 크기를 해석합니다. 공분산 점수의 수가 큰 양수이거나 큰 음수 인 경우이를 양수 또는 음수로 강력하게 연결된 두 데이터 요소로 해석 할 수 있습니다.
공분산의 크기를 해석합니다. 공분산 점수의 수가 큰 양수이거나 큰 음수 인 경우이를 양수 또는 음수로 강력하게 연결된 두 데이터 요소로 해석 할 수 있습니다. - 표본 데이터 세트의 -8.07 공분산은 상당히 큽니다. 데이터의 범위는 1에서 12까지입니다. 따라서 8은 상당히 큰 수입니다. 이것은 데이터 세트 x와 y 사이에 상당히 강한 관계를 나타냅니다.
 관계의 부족을 이해하십시오. 결과가 0과 같거나 매우 가까운 공분산이면 데이터 포인트가 관련이 없다는 결론을 내릴 수 있습니다. 즉, 한 값이 증가해도 다른 값이 증가 할 필요는 없습니다. 두 용어는 거의 무작위로 연결됩니다.
관계의 부족을 이해하십시오. 결과가 0과 같거나 매우 가까운 공분산이면 데이터 포인트가 관련이 없다는 결론을 내릴 수 있습니다. 즉, 한 값이 증가해도 다른 값이 증가 할 필요는 없습니다. 두 용어는 거의 무작위로 연결됩니다. - 신발 사이즈를 시험 성적과 관련 시킨다고 가정 해 보겠습니다. 학생의 시험 성적에 영향을 미치는 요인이 너무 많기 때문에 0에 가까운 공분산 점수를 기대할 수 있습니다. 이는 두 값 사이에 거의 관계가 없음을 나타냅니다.
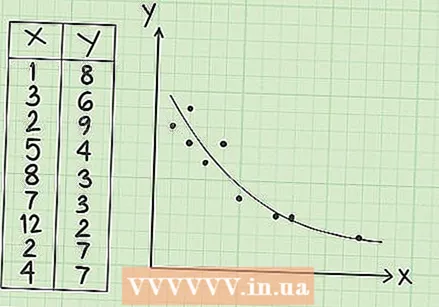 관계를 그래픽으로 봅니다. 공분산을 시각적으로 이해하기 위해 x, y 그래프에 데이터 포인트를 플로팅 할 수 있습니다. 이렇게하면 점이 정확히 직선이 아니지만 왼쪽 상단에서 오른쪽 하단으로 대각선으로 클러스터에 접근하는 경향이 있음을 쉽게 알 수 있습니다. 이것은 음의 공분산에 대한 설명입니다. 또한 공분산 값이 -8.07과 같다는 것을 알 수 있습니다. 이것은 데이터 포인트에 비해 상당히 많은 수입니다. 높은 숫자는 데이터 포인트의 선형 모양에서 추론 할 수있는 공분산이 매우 강력 함을 나타냅니다.
관계를 그래픽으로 봅니다. 공분산을 시각적으로 이해하기 위해 x, y 그래프에 데이터 포인트를 플로팅 할 수 있습니다. 이렇게하면 점이 정확히 직선이 아니지만 왼쪽 상단에서 오른쪽 하단으로 대각선으로 클러스터에 접근하는 경향이 있음을 쉽게 알 수 있습니다. 이것은 음의 공분산에 대한 설명입니다. 또한 공분산 값이 -8.07과 같다는 것을 알 수 있습니다. 이것은 데이터 포인트에 비해 상당히 많은 수입니다. 높은 숫자는 데이터 포인트의 선형 모양에서 추론 할 수있는 공분산이 매우 강력 함을 나타냅니다. - 다시 한번 살펴 보려면 wikiHow의 좌표계에서 점 그리기에 대한 기사를 읽어보세요.
경고
- 공분산은 통계에 제한적으로 적용됩니다. 종종 상관 계수 또는 기타 개념을 계산하는 단계입니다. 공분산 점수에 기반한 지나치게 대담한 해석에주의하십시오.



