작가:
Carl Weaver
창조 날짜:
23 2 월 2021
업데이트 날짜:
28 6 월 2024

콘텐츠
표준 편차를 계산하여 샘플 데이터에서 스프레드를 찾을 수 있습니다. 그러나 먼저 샘플의 평균과 분산과 같은 몇 가지 양을 계산해야 합니다. 분산은 평균을 중심으로 한 데이터의 분포를 측정한 것입니다. 표준 편차는 표본 분산의 제곱근과 같습니다. 이 기사에서는 평균, 분산 및 표준 편차를 찾는 방법을 보여줍니다.
단계
파트 1/3: 평균
 1 데이터 세트를 가져옵니다. 평균은 통계 계산에서 중요한 양입니다.
1 데이터 세트를 가져옵니다. 평균은 통계 계산에서 중요한 양입니다. - 데이터 세트의 숫자 수를 결정합니다.
- 집합의 숫자가 서로 매우 다르거나 매우 가깝습니까(소수 부분에 따라 다름)?
- 데이터 세트의 숫자는 무엇을 나타냅니까? 테스트 점수, 심박수, 키, 체중 등.
- 예를 들어, 일련의 테스트 점수: 10, 8, 10, 8, 8, 4.
 2 평균을 계산하려면 데이터 세트의 모든 숫자가 필요합니다.
2 평균을 계산하려면 데이터 세트의 모든 숫자가 필요합니다.- Average는 데이터세트에 있는 모든 숫자의 평균입니다.
- 평균을 계산하려면 데이터 세트의 모든 숫자를 더하고 결과 값을 데이터 세트의 총 숫자 수(n)로 나눕니다.
- 이 예에서는 (10, 8, 10, 8, 8, 4) n = 6입니다.
 3 데이터 세트의 모든 숫자를 더하십시오.
3 데이터 세트의 모든 숫자를 더하십시오.- 이 예에서 숫자는 10, 8, 10, 8, 8, 4입니다.
- 10 + 8 + 10 + 8 + 8 + 4 = 48. 이것은 데이터 세트에 있는 모든 숫자의 합입니다.
- 답을 확인하려면 숫자를 다시 추가하세요.
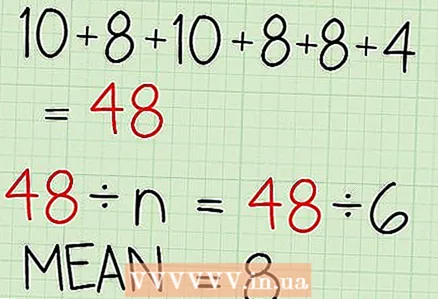 4 숫자의 합을 샘플의 숫자(n) 수로 나눕니다. 평균을 찾을 수 있습니다.
4 숫자의 합을 샘플의 숫자(n) 수로 나눕니다. 평균을 찾을 수 있습니다. - 이 예에서(10, 8, 10, 8, 8 및 4) n = 6입니다.
- 이 예에서 숫자의 합은 48입니다. 따라서 48을 n으로 나눕니다.
- 48/6 = 8
- 이 표본의 평균값은 8입니다.
파트 2/3: 분산
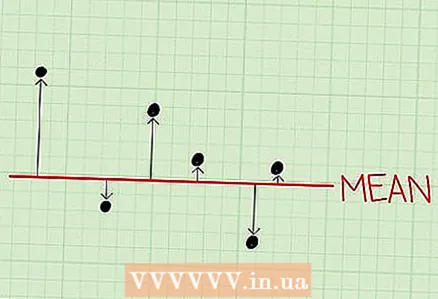 1 분산을 계산합니다. 평균 주변의 데이터 분산을 측정한 것입니다.
1 분산을 계산합니다. 평균 주변의 데이터 분산을 측정한 것입니다. - 이 값은 샘플 데이터가 어떻게 흩어져 있는지에 대한 아이디어를 제공합니다.
- 저분산 표본에는 평균과 크게 다르지 않은 데이터가 포함됩니다.
- 분산이 높은 표본에는 평균과 매우 다른 데이터가 포함됩니다.
- 분산은 종종 두 데이터 세트의 분포를 비교하는 데 사용됩니다.
 2 데이터 세트의 각 숫자에서 평균을 뺍니다. 데이터 세트의 각 값이 평균과 얼마나 다른지 알 수 있습니다.
2 데이터 세트의 각 숫자에서 평균을 뺍니다. 데이터 세트의 각 값이 평균과 얼마나 다른지 알 수 있습니다. - 이 예(10, 8, 10, 8, 8, 4)에서 평균은 8입니다.
- 10 - 8 = 2; 8 - 8 = 0, 10 - 2 = 8, 8 - 8 = 0, 8 - 8 = 0, 4 - 8 = -4.
- 빼기를 다시 수행하여 각 답을 확인하십시오. 이 값은 다른 수량을 계산할 때 필요하기 때문에 매우 중요합니다.
 3 이전 단계에서 얻은 각 값을 제곱합니다.
3 이전 단계에서 얻은 각 값을 제곱합니다.- 이 샘플의 각 숫자(10, 8, 10, 8, 8, 4)에서 평균(8)을 빼면 2, 0, 2, 0, 0, -4 값이 나옵니다.
- 2, 0, 2, 0, 0 및 (-4) = 4, 0, 4, 0, 0, 16 값을 제곱합니다.
- 다음 단계로 진행하기 전에 답을 확인하세요.
 4 값의 제곱을 더합니다. 즉, 제곱의 합을 구합니다.
4 값의 제곱을 더합니다. 즉, 제곱의 합을 구합니다.- 이 예에서 값의 제곱은 4, 0, 4, 0, 0, 16입니다.
- 값은 각 샘플 번호에서 평균을 빼서 얻은 것임을 기억하십시오. (10-8) ^ 2 + (8-8) ^ 2 + (10-2) ^ 2 + (8-8) ^ 2 + ( 8-8 ) ^ 2 + (4-8) ^ 2
- 4 + 0 + 4 + 0 + 0 + 16 = 24.
- 제곱의 합은 24입니다.
 5 제곱합을 (n-1)로 나눕니다. n은 샘플의 데이터(숫자) 양입니다. 이런 식으로 분산을 얻습니다.
5 제곱합을 (n-1)로 나눕니다. n은 샘플의 데이터(숫자) 양입니다. 이런 식으로 분산을 얻습니다. - 이 예에서는 (10, 8, 10, 8, 8, 4) n = 6입니다.
- n-1 = 5.
- 이 예에서 제곱합은 24입니다.
- 24/5 = 4,8
- 이 표본의 분산은 4.8입니다.
3/3부: 표준 편차
 1 표준 편차를 계산하기 위해 분산을 찾습니다.
1 표준 편차를 계산하기 위해 분산을 찾습니다.- 분산은 평균을 중심으로 한 데이터의 퍼짐을 측정한 것임을 기억하십시오.
- 표준 편차는 표본의 데이터 분포를 설명하는 유사한 양입니다.
- 이 예에서 분산은 4.8입니다.
 2 분산의 제곱근을 취하여 표준 편차를 찾습니다.
2 분산의 제곱근을 취하여 표준 편차를 찾습니다.- 일반적으로 모든 데이터의 68%가 평균의 1 표준 편차 내에 있습니다.
- 이 예에서 분산은 4.8입니다.
- √4.8 = 2.19. 이 표본의 표준편차는 2.19입니다.
- 이 표본(10, 8, 10, 8, 8, 4)의 6개 숫자 중 5개(83%)가 평균(8)에서 1 표준 편차(2.19) 내에 있습니다.
 3 평균, 분산 및 표준 편차가 올바르게 계산되었는지 확인합니다. 이렇게 하면 답변을 확인할 수 있습니다.
3 평균, 분산 및 표준 편차가 올바르게 계산되었는지 확인합니다. 이렇게 하면 답변을 확인할 수 있습니다. - 계산을 기록해 두십시오.
- 계산 확인 중 다른 값이 나오면 처음부터 모든 계산을 확인하세요.
- 실수한 부분을 찾을 수 없으면 처음부터 계산하십시오.

을 연주하는 방법")

