작가:
Charles Brown
창조 날짜:
9 2 월 2021
업데이트 날짜:
1 칠월 2024
콘텐츠
제곱합 또는 SSE는 다른 데이터 값으로 이어지는 예비 통계 계산입니다. 데이터 값 세트가있는 경우 이러한 값이 얼마나 밀접하게 관련되어 있는지 확인할 수 있으면 유용합니다. 데이터를 테이블로 구성한 다음 매우 간단한 계산을 수행해야합니다. 데이터 세트에 대한 SSE를 찾으면 분산 및 표준 편차를 찾을 수 있습니다.
단계로
방법 1/3 : SSE를 직접 계산
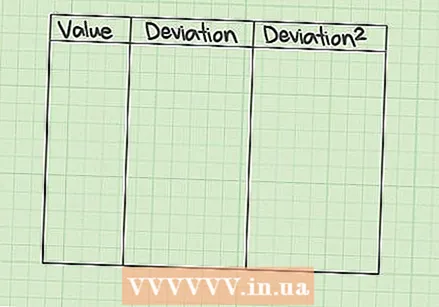 3 열 테이블을 만듭니다. SSE를 계산하는 가장 명확한 방법은 3 열 테이블로 시작하는 것입니다. 세 개의 열에 레이블 지정
3 열 테이블을 만듭니다. SSE를 계산하는 가장 명확한 방법은 3 열 테이블로 시작하는 것입니다. 세 개의 열에 레이블 지정  세부 사항을 입력하십시오. 첫 번째 열에는 측정 값이 포함됩니다. 열 채우기
세부 사항을 입력하십시오. 첫 번째 열에는 측정 값이 포함됩니다. 열 채우기  평균을 계산하십시오. 각 측정에 대한 오류를 계산하기 전에 전체 데이터 세트의 평균을 계산해야합니다.
평균을 계산하십시오. 각 측정에 대한 오류를 계산하기 전에 전체 데이터 세트의 평균을 계산해야합니다. - 데이터 세트의 평균은 세트의 값 수로 나눈 값의 합계입니다. 이것은 변수를 사용하여 기호로 나타낼 수 있습니다.
 개별 오류 값을 계산합니다. 표의 두 번째 열에 각 데이터 값에 대한 오류 값을 입력해야합니다. 오차는 측정 값과 평균값의 차이입니다.
개별 오류 값을 계산합니다. 표의 두 번째 열에 각 데이터 값에 대한 오류 값을 입력해야합니다. 오차는 측정 값과 평균값의 차이입니다. - 주어진 데이터 세트에 대해 각 측정 값에서 평균 98.87을 빼고 두 번째 열에 결과를 채 웁니다. 이 10 가지 계산은 다음과 같이 진행됩니다.
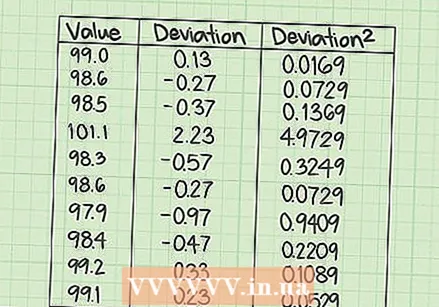 SSE를 계산하십시오. 표의 세 번째 열에서 중간 열의 각 결과 값의 제곱을 찾으십시오. 이는 각 측정 데이터 값에 대한 평균 편차의 제곱을 나타냅니다.
SSE를 계산하십시오. 표의 세 번째 열에서 중간 열의 각 결과 값의 제곱을 찾으십시오. 이는 각 측정 데이터 값에 대한 평균 편차의 제곱을 나타냅니다. - 중간 열의 각 값에 대해 계산기를 사용하여 제곱을 계산합니다. 다음과 같이 세 번째 열에 결과를 기록합니다.
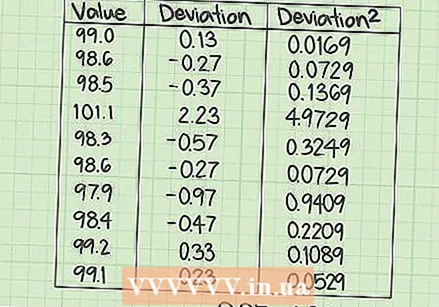 오류의 제곱을 더하십시오. 마지막 단계는 세 번째 열에서 값의 합계를 찾는 것입니다. 원하는 결과는 SSE 또는 오류 제곱의 합입니다.
오류의 제곱을 더하십시오. 마지막 단계는 세 번째 열에서 값의 합계를 찾는 것입니다. 원하는 결과는 SSE 또는 오류 제곱의 합입니다. - 이 데이터 세트의 경우 SSE는 세 번째 열에 10 개의 값을 추가하여 계산됩니다.
 스프레드 시트의 열에 레이블을 지정합니다. Excel에서 위와 같은 세 개의 머리글을 사용하여 세 개의 열이있는 테이블을 만듭니다.
스프레드 시트의 열에 레이블을 지정합니다. Excel에서 위와 같은 세 개의 머리글을 사용하여 세 개의 열이있는 테이블을 만듭니다. - A1 셀에 제목으로 "값"을 입력합니다.
- 상자 B1에 제목으로 "편차"를 입력합니다.
- 상자 C1에 제목으로 "Deviation squared"를 입력합니다.
 세부 정보를 입력하십시오. 첫 번째 열에 측정 값을 입력해야합니다. 세트가 작 으면 손으로 쉽게 입력 할 수 있습니다. 큰 데이터 세트가있는 경우 데이터를 복사하여 열에 붙여 넣어야 할 수 있습니다.
세부 정보를 입력하십시오. 첫 번째 열에 측정 값을 입력해야합니다. 세트가 작 으면 손으로 쉽게 입력 할 수 있습니다. 큰 데이터 세트가있는 경우 데이터를 복사하여 열에 붙여 넣어야 할 수 있습니다. 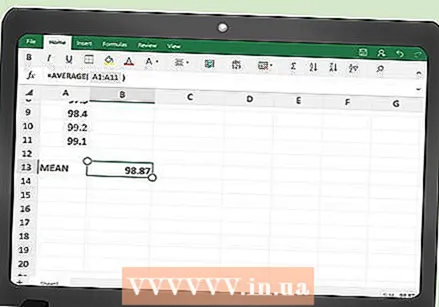 데이터 포인트의 평균을 결정하십시오. Excel에는 평균을 계산하는 기능이 있습니다. 데이터 표 아래의 빈 셀 (선택한 셀은 중요하지 않음)에 다음을 입력합니다.
데이터 포인트의 평균을 결정하십시오. Excel에는 평균을 계산하는 기능이 있습니다. 데이터 표 아래의 빈 셀 (선택한 셀은 중요하지 않음)에 다음을 입력합니다. - = 평균 (A2 : ___)
- 공백을 입력하지 마십시오. 마지막 데이터 포인트의 셀 이름으로 해당 공간을 채우십시오. 예를 들어 100 개의 데이터 포인트가있는 경우 다음 함수를 사용합니다.
- = 평균 (A2 : A101)
- 이 함수에는 A2에서 A101까지의 데이터가 포함됩니다. 맨 위 행에는 열 머리글이 포함되어 있기 때문입니다.
- Enter 키를 누르거나 테이블의 다른 셀을 클릭하면 새로 프로그래밍 된 셀이 데이터 값의 평균으로 자동으로 채워집니다.
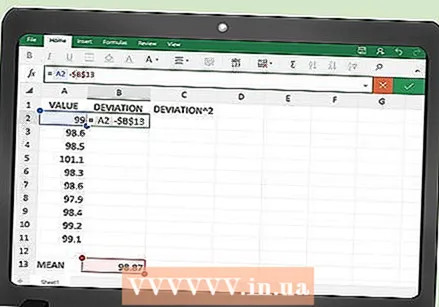 오류 측정을위한 기능을 입력합니다. "편차"열의 첫 번째 빈 셀에 각 데이터 요소와 평균 간의 차이를 계산하는 함수를 입력합니다. 이렇게하려면 평균이있는 셀 이름을 사용하십시오. 지금은 A104 셀을 사용했다고 가정 해 보겠습니다.
오류 측정을위한 기능을 입력합니다. "편차"열의 첫 번째 빈 셀에 각 데이터 요소와 평균 간의 차이를 계산하는 함수를 입력합니다. 이렇게하려면 평균이있는 셀 이름을 사용하십시오. 지금은 A104 셀을 사용했다고 가정 해 보겠습니다. - B2 셀에 입력하는 오류 계산 함수는 다음과 같습니다.
- = A2- $ A $ 104. 달러 기호는 계산을 위해 상자 A104를 잠그는 데 필요합니다.
- B2 셀에 입력하는 오류 계산 함수는 다음과 같습니다.
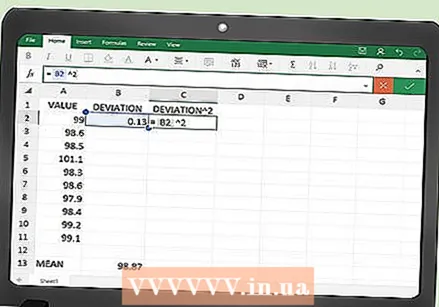 제곱 오차에 대한 함수를 입력하십시오. 세 번째 열에서 원하는 제곱을 계산하도록 Excel에 지시 할 수 있습니다.
제곱 오차에 대한 함수를 입력하십시오. 세 번째 열에서 원하는 제곱을 계산하도록 Excel에 지시 할 수 있습니다. - C2 셀에 다음 함수를 입력하십시오.
- = B2 ^ 2
- C2 셀에 다음 함수를 입력하십시오.
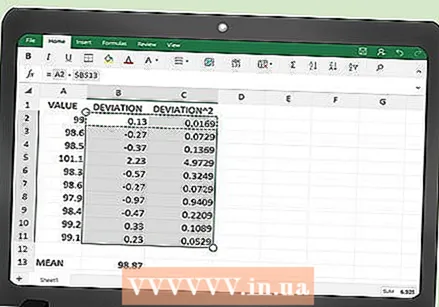 함수를 복사하여 전체 테이블을 채 웁니다. 각 열의 맨 위 셀, B2 및 C2에 함수를 입력 한 후 전체 테이블을 채워야합니다. 테이블의 아무 줄 에나 함수를 다시 입력 할 수 있지만 너무 오래 걸립니다. 마우스를 사용하여 B2 및 C2 셀을 함께 강조 표시하고 마우스 단추를 놓지 않고 각 열의 맨 아래 셀로 끕니다.
함수를 복사하여 전체 테이블을 채 웁니다. 각 열의 맨 위 셀, B2 및 C2에 함수를 입력 한 후 전체 테이블을 채워야합니다. 테이블의 아무 줄 에나 함수를 다시 입력 할 수 있지만 너무 오래 걸립니다. 마우스를 사용하여 B2 및 C2 셀을 함께 강조 표시하고 마우스 단추를 놓지 않고 각 열의 맨 아래 셀로 끕니다. - 테이블에 100 개의 데이터 포인트가 있다고 가정하고 마우스를 B101 및 C101 셀로 드래그합니다.
- 마우스 버튼을 놓으면 공식이 테이블의 모든 셀에 복사됩니다. 계산 된 값으로 테이블이 자동으로 채워 져야합니다.
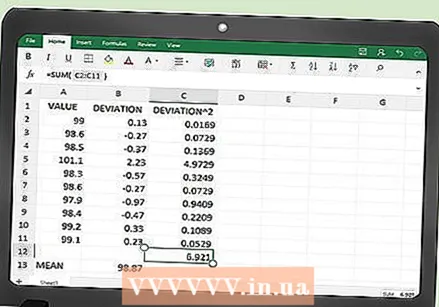 SSE를 찾으십시오. 테이블의 C 열에는 모든 제곱 오차 값이 포함됩니다. 마지막 단계는 Excel에서 이러한 값의 합계를 계산하도록하는 것입니다.
SSE를 찾으십시오. 테이블의 C 열에는 모든 제곱 오차 값이 포함됩니다. 마지막 단계는 Excel에서 이러한 값의 합계를 계산하도록하는 것입니다. - 표 아래의 셀 (이 예에서는 C102)에 다음 함수를 입력합니다.
- = 합계 (C2 : C101)
- Enter를 클릭하거나 테이블의 다른 셀을 클릭하면 데이터의 SSE 값을 얻을 수 있습니다.
- 표 아래의 셀 (이 예에서는 C102)에 다음 함수를 입력합니다.
- 중간 열의 각 값에 대해 계산기를 사용하여 제곱을 계산합니다. 다음과 같이 세 번째 열에 결과를 기록합니다.
- 주어진 데이터 세트에 대해 각 측정 값에서 평균 98.87을 빼고 두 번째 열에 결과를 채 웁니다. 이 10 가지 계산은 다음과 같이 진행됩니다.
- 데이터 세트의 평균은 세트의 값 수로 나눈 값의 합계입니다. 이것은 변수를 사용하여 기호로 나타낼 수 있습니다.
방법 3/3 : SSE를 다른 통계에 연결
 SSE에서 편차를 계산하십시오. 데이터 세트에 대한 SSE를 찾는 것은 일반적으로 더 유용한 다른 값을 찾기위한 빌딩 블록입니다. 첫 번째는 분산입니다. 분산은 측정 된 데이터가 평균에서 얼마나 벗어나는지 측정 한 것입니다. 실제로는 평균과 차이를 제곱 한 평균입니다.
SSE에서 편차를 계산하십시오. 데이터 세트에 대한 SSE를 찾는 것은 일반적으로 더 유용한 다른 값을 찾기위한 빌딩 블록입니다. 첫 번째는 분산입니다. 분산은 측정 된 데이터가 평균에서 얼마나 벗어나는지 측정 한 것입니다. 실제로는 평균과 차이를 제곱 한 평균입니다. - SSE는 제곱 오차의 합이므로 값의 수로 나누기 만하면 평균 (분산)을 찾을 수 있습니다. 그러나 전체 모집단이 아닌 표본 계열의 분산을 계산하는 경우 분산을 n 대신 (n-1)로 나눕니다. 그래서:
- 분산 = SSE / n, 전체 모집단의 분산을 계산하는 경우.
- 분산 = SSE / (n-1), 데이터 샘플의 분산을 계산할 때.
- 환자 체온의 표본 추출 문제는 10 명의 환자가 표본 일 뿐이라고 가정 할 수 있습니다. 따라서 분산은 다음과 같이 계산됩니다.
 SSE의 표준 편차를 계산합니다. 표준 편차는 데이터 세트의 값이 평균에서 얼마나 벗어나는지를 나타내는 일반적으로 사용되는 값입니다. 표준 편차는 분산의 제곱근입니다. 분산은 제곱 오차 측정의 평균이라는 것을 기억하십시오.
SSE의 표준 편차를 계산합니다. 표준 편차는 데이터 세트의 값이 평균에서 얼마나 벗어나는지를 나타내는 일반적으로 사용되는 값입니다. 표준 편차는 분산의 제곱근입니다. 분산은 제곱 오차 측정의 평균이라는 것을 기억하십시오. - 따라서 SSE를 계산 한 후 다음과 같은 표준 편차를 찾을 수 있습니다.
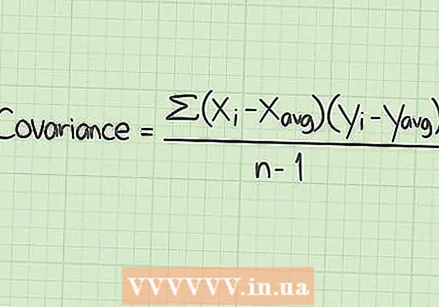 SSE를 사용하여 공분산을 확인합니다. 이 기사에서는 한 번에 하나의 값만 측정하는 데이터 세트에 중점을 둡니다. 그러나 많은 연구에서 두 개의 개별 값을 비교할 수 있습니다. 예를 들어,이 두 값이 데이터 세트의 평균뿐만 아니라 서로 어떻게 관련되는지 알고 싶습니다. 이 값이 공분산입니다.
SSE를 사용하여 공분산을 확인합니다. 이 기사에서는 한 번에 하나의 값만 측정하는 데이터 세트에 중점을 둡니다. 그러나 많은 연구에서 두 개의 개별 값을 비교할 수 있습니다. 예를 들어,이 두 값이 데이터 세트의 평균뿐만 아니라 서로 어떻게 관련되는지 알고 싶습니다. 이 값이 공분산입니다. - 공분산 계산은 각 데이터 유형에 대해 SSE를 사용한 다음이를 비교한다는 점을 제외하면 여기에서 설명하기에는 너무 자세합니다. 공분산 및 관련 계산에 대한 자세한 설명은 위키 하우에서이 주제에 대한 기사를 찾을 수 있습니다.
- 공분산 사용의 예로, 의학 연구에서 환자의 나이를 발열 온도를 낮추는 약물의 효과와 비교할 수 있습니다. 그런 다음 하나의 연령 데이터 세트와 두 번째 온도 데이터 세트가 있습니다. 그런 다음 각 데이터 세트에 대한 SSE를 찾고 거기에서 분산, 표준 편차 및 공분산을 찾습니다.
- 따라서 SSE를 계산 한 후 다음과 같은 표준 편차를 찾을 수 있습니다.
- SSE는 제곱 오차의 합이므로 값의 수로 나누기 만하면 평균 (분산)을 찾을 수 있습니다. 그러나 전체 모집단이 아닌 표본 계열의 분산을 계산하는 경우 분산을 n 대신 (n-1)로 나눕니다. 그래서:



